
本文分析并介绍 Oracle 中的分页查找的方法。
Oracle 中的表,除了我们建表时设计的各个字段,其实还有两个字段(此处只介绍2个),分别是 ROWID(行标示符)和 ROWNUM(行号),即使我们使用DESCRIBE命令查看表的结构,也是看不到这两个列的描述的,因为,他们其实是只在数据库内部使用的,所以也通常称他们为伪列(pseudo column)。
下面我们先建表并添加一些数据来验证上面的说明。
建表:
create table users(id integer primary key,name nvarchar2(20))
插入数据:
insert into users(id,name) values(1,'tom');insert into users(id,name) values(2,'cat');insert into users(id,name) values(3,'bob');insert into users(id,name) values(4,'anxpp');insert into users(id,name) values(5,'ez');insert into users(id,name) values(6,'lily');
使用describe命令查看表结构:
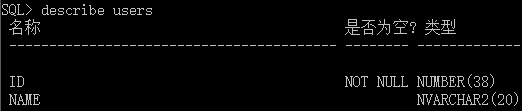
可以看到,确实只有建表时的两个字段。
但我们可以查询的时候,查找到伪列的值:
select rowid,rownum,id,name from users;
结果:
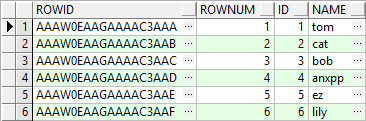
这个 rowid 我们一般用不到,Oracle 数据库内部使用它来存储行的物理位置,是一个 18 位的数字,采用 base-64 编码。
而这个 rownum,我们也正是使用它来进行分页查询的,它的值,就是表示的该行的行号。
对于分页,我们只要想办法可以查询到从某一起始行到终止行就可以的,分页的逻辑可以放到程序里面。
于是,我们理所当然会想到如下语句查询第 2 页的数据(每页2条数据,页码从 1 开始,所以起始行的行号为 (页码-1) * 每页长度 +1=3,终止行的行号为 页码*每页长度=4 )。
select * from users where rownum>=3 rownum <= 4;
哈哈!是不是发现没有任何结果,原因很简单,Oracle机制就是这样的:因为第一条数据行号为1,不符合>=3的条件,所以第一行被去掉,之前的第二行变为新的第一行(即这个行号不是写死的,可以理解为是动态的),如此下去,一直到最后一行,条件始终没法满足,所以就一条数据也查不出来。
既然找到了原因,解决方法也就很明显了,我们只要将行号查询出来生成一个结果集,然后再从这个结果集中,选择行号大于我们设定的那个值就可以了,上面的分页查找正确的写法应该是这样:
select id,name from(select rownum rn,u.* from users u) uawhere ua.rn between 3 and 4;
上面的语句还可以优化:>= 不能用,但是 <= 是可以的,我们不需要在子查询中将结果全部查出来,首先使用终止行筛选子查询的结果,SQL如下:
select id,name from(select rownum rn,u.* from users u where rownum<=4) uawhere ua.rn >= 3;
结果:

很多时候,我们并不是盲目的分页查找的,二十按某一个或多个字段的升序或降序分页,即包含 order by 语句的分页查询,我们先看一下 order by 的查询结果中 rownum 是怎样的:
select rownum,id,name from users order by name;
结果:
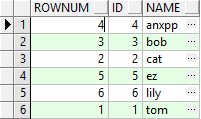
可以看到,我们说行号完全是动态的,也是不准确的,这时候的行号并不是经过 order by 后新结果的增序行号。
但有了上面的嵌套查询的经验,这里也可以好好应用一下,怎么做呢:先查找出排序好的结果集,然后应用上面的方法得到最终结果,sql 如下:
select id,name from((select rownum rn,uo.* from(select * from users u order by name) uowhere rownum<=4)) uawhere ua.rn>=3;
按照上面的结果,正确的分页结果应该是 id 为 2 和 5 的,看下结果:
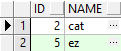
OK,结果正确。
其实连表查询之类的,也是差不多的,多点嵌套而已,掌握了原理,随便分析一下就能写出对应的 SQL 了,而编写 SQL 时,我们也得动动脑子,毕竟 SQL 也是由优劣之分的。
原文写得很好可以看下!
本文转载自: